8. 实践案例:制作Lens Protocol的数据看板(一)
为了让大家尽快上手开始数据分析,我们会将一些偏理论的内容放到教程的后续部分,前半部分则更多讲解一些可以结合起来实践的内容。本篇教程我们一起来为Lens Protocol项目制作一个数据看板。
Lens协议是什么?
来自Lens官网的介绍整理如下: Lens协议(Lens Protocol,简称 Lens)是Polygon区块链上的 Web3 社交图谱生态系统。它旨在让创作者拥有自己与社区之间的联系,形成一个完全可组合的、用户拥有的社交图谱。该协议从一开始就考虑到了模块化,允许添加新功能和修复问题,同时确保用户拥有的内容和社交关系不可变。Lens旨在解决现有社交媒体网络中的一些主要问题。Web2 网络都从其专有的集中式数据库中读取数据。用户的个人资料、朋友关系和内容被锁定在特定网络中,其所有权归网络运营商拥有。各网络之间互相竞争,争夺用户注意力,变成一种零和游戏。Lens通过成为用户拥有的、任何应用程序都可以接入的开放社交图谱来纠正这一点。由于用户拥有自己的数据,他们可以将其带到任何基于Lens协议构建的应用程序中。作为其内容的真正所有者,创作者不再需要担心基于单个平台的算法和政策的突然变化而失去他们的内容、观众和收入来源。此外,使用Lens协议的每个应用程序都有益于整个生态系统,从而将零和游戏变成了协作游戏。
Lens协议里面主要涉及以下角色(实体):个人资料(Profile)、出版物(Publication)、评论(Comment)、镜像(Mirror)、收藏(Collect))、关注(Follow)。同时,协议里面存在3种类型的NFT,即:个人资料NFT(Profile NFT)、关注NFT(Follow NFT)、收藏NFT(Collect NFT)。
Lens上的典型使用场景包括:
- 创作者注册创建他们的Profile,铸造其专属的ProfileNFT。可以设置个性化名称(Profile Handle Name,可简单类比为域名,即“Lens域名”)。同时,可以设置账号头像图片URL、被关注时的规则(通过设置特殊的规则,可以产生收益,比如可以设置用户需要支付一定的费用才能关注Profile)。目前仅许可名单内的地址可以创建个人资料账号。
- 创作者发布内容出版物(Publication),包括文章(帖子,Post)、镜像(Mirror)、评论(Comment)等。
- 普通用户可以关注创作者,收藏感兴趣的出版物。
- 在相关操作步骤中,3种不同类型NFT被分别铸造并传输给不同的用户地址。
Lens 协议主要分析内容
针对Lens这样的项目,我们可以从整体上分析其概况,也可以从不同角度、针对其中的不同角色类型进行数据分析。以下是一些可以分析的内容的概况:
- 总用户数量、总的创作者数量、创作者占比等
- 总出版物数量、总评论数量、总镜像数量、总关注数量、总收藏数量等
- 用户相关的分析:每日新增用户数量、每日新增创作者数量、每日活跃用户数量、活跃创作者数量、用户整体活跃度的变化趋势等
- Lens账号个性化域名的相关分析:域名注册数量、不同类型域名的注册情况(纯数字、纯字母、不同长度)等
- 创作者的活跃度分析:发布出版物的数量、被关注的次数、被镜像的次数、最热门创作者等
- 出版物的相关分析:内容发布数量、增长趋势、被关注次数、被收藏次数、最热门出版物等
- 关注的相关分析:关注的数量及其变化趋势、关注者的成本分析、关注创作者最多的用户等
- 收藏的相关分析:每日收藏数量、热门收藏等
- 创作者的收益分析:通过关注产生的收益、其他收益等
- 从NFT的角度进行相关分析:每日铸造数量、涉及的成本(关注费用)等
可以分析的内容非常丰富。在这个看板中,我们仅使用部分内容做案例。其他内容请大家分别去尝试分析。
数据表介绍
在Lens的官方文档已部署的智能合约页面,提示使用LensHub代理(LensHub Proxy)这个智能合约作为交互的主要合约。除了少部分和NFT相关的查询需要用到智能合约FollowNFT下的数据表外,我们基本上主要关注LensHub这个智能合约下面的已解析表就可以了。下图列出了这个智能合约下部分数据表。
之前的教程提过,已解析的智能合约数据表有两大类型:事件日志表(Event Log)和函数调用表(Function Call)。两种类型的表分别以:projectname_blockchain.contractName_evt_eventName和:projectname_blockchain.contractName_call_functionName格式命名。浏览LensHub合约下的表格列表,我们可以看到下面这些主要的数据表:
- 收藏表(collect/collectWithSig)
- 评论表(comment/commentWithSig)
- 个人资料表(createProfile)
- 关注表(follow/followWithSig)
- 镜像表(mirror/mirrorWithSig)
- 帖子表(post/postWithSig)
- Token传输表(Transfer)
除了Token传输表是事件表之外,上述其他表格都是函数调用表。其中后缀带有WithSig的数据表,表示通过签名(Signature)授权来执行的操作。通过签名授权,可以方便地通过API或者允许其他授权方代表某个用户执行某项操作。当我们分析帖子表等类型时,需要将相关表里的数据集合到一起进行分析。
大家可以在列表中看到还有其他很多不同方法的数据表,由于这些表全部都是在LensHub智能合约下生成的,所以他们交互的contract_address全部都是LensHub这个地址,即0xdb46d1dc155634fbc732f92e853b10b288ad5a1d。当我们要分析Lens的总体用户数据时,应该使用polygon.transactions 原始表,查询其中与这个合约地址交互的数据,这样才能得到完整的数据。
Lens协议概览分析
通过查看LensHub智能合约创建交易详情,我们可以看到该智能合约部署与2022年5月16日。当我们查询polygon.transactions原始表这样的原始数据表时,通过设置日期时间过滤条件,可以极大地提高查询执行性能。
总交易数量和总用户数量
如前所述,最准确的查询用户数量的数据源是polygon.transactions原始表,我们可以使用如下的query来查询Lens当前的交易数量和总用户数量。我们直接查询发送给LensHub智能合约的全部交易记录,通过distinct关键字来统计独立用户地址数量。由于我们已知该智能合约的创建日期,所以用这个日期作为过滤条件来优化查询性能。
select count(*) as transaction_count,
count(distinct "from") as user_count -- count unique users
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date
创建一个新的查询,使用上面的SQL代码,运行查询得到结果后,保存Query。然后为其添加两个Counter类型到可视化图表,标题分别设置为“Lens Total Transactions”和“Lens Total Users”。
本查询在Dune上的参考链接:https://dune.com/queries/1533678
现在我们可以将可视化图表添加到数据看板。由于这是我们的第一个查询,我们可以在添加可视化图表到数据看板的弹出对话框中创建新的数据看板。切换到第一个Counter,点击“Add to dashboard”按钮,在对话框中,点击底部的“New dashboard”按钮,输入数据看板的名称后,点击“Save dashboard”按钮创建空白的数据看板。我这里使用“Lens Protocol Ecosystem Analysis”作为看板的名称。保存之后我们就可以在列表中看到刚创建的数据看板,点击其右边的“Add”按钮,就可以将当前Counter添加到数据看板中。关闭对话框后切换到另一个Counter,也将其添加到新创建的数据看板。
此时,我们可以点击Dune网站头部的“My Creations”链接,再选择“Dashboards” Tab来切换到数据看板列表。点击我们新创建的看板名称,进入看板的预览界面。我们可以看到刚才添加的两个Counter类型可视化图表。在这里,通过点击“Edit”按钮进入编辑模式,你可以对图表的大小、位置做相应的调整,可以通过点击“”按钮来添加文本组件,对数据看板做一些说明或者美化。下图是调整后的数据看板的界面示例。
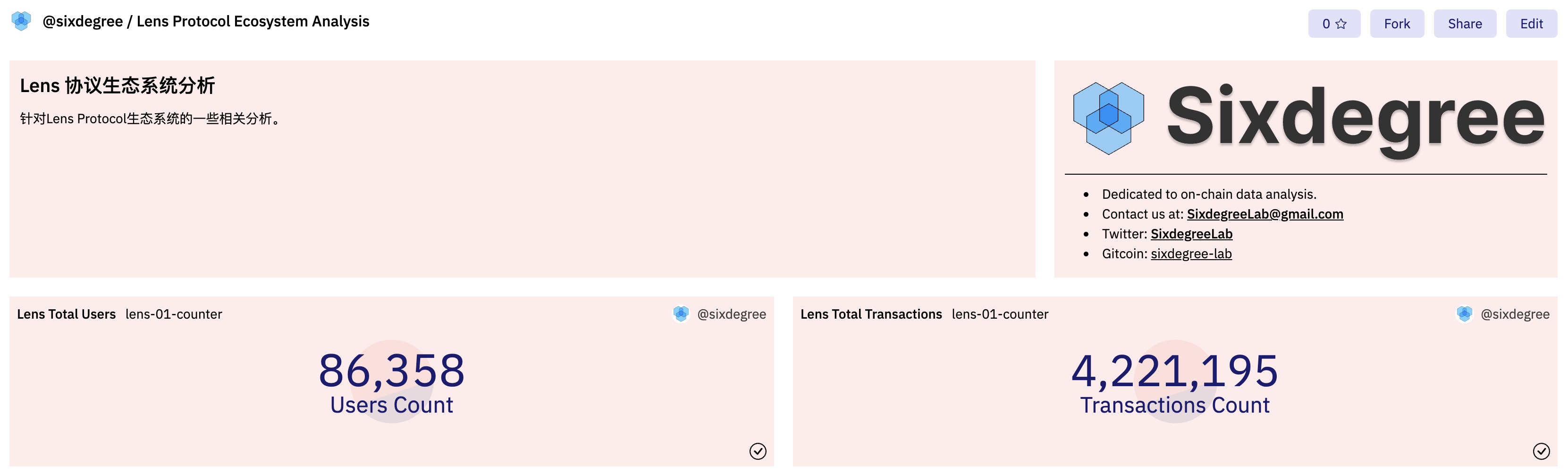
我们新创建的数据看板的链接是:Lens Protocol Ecosystem Analysis
按天统计的交易数量和独立用户数量
要想分析Lens协议在活跃度方面的增长变化趋势,我们可以创建一个查询,按日期来统计每天的交易数量和活跃用户地址数量。通过在查询中添加block_time字段并使用date_trunc()函数将其转换为日期(不含时分秒数值部分),结合group by查询子句,我们就可以统计出每天的数据。查询代码如下所示:
select date_trunc('day', block_time) as block_date,
count(*) as transaction_count,
count(distinct "from") as user_count
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date
group by 1
order by 1
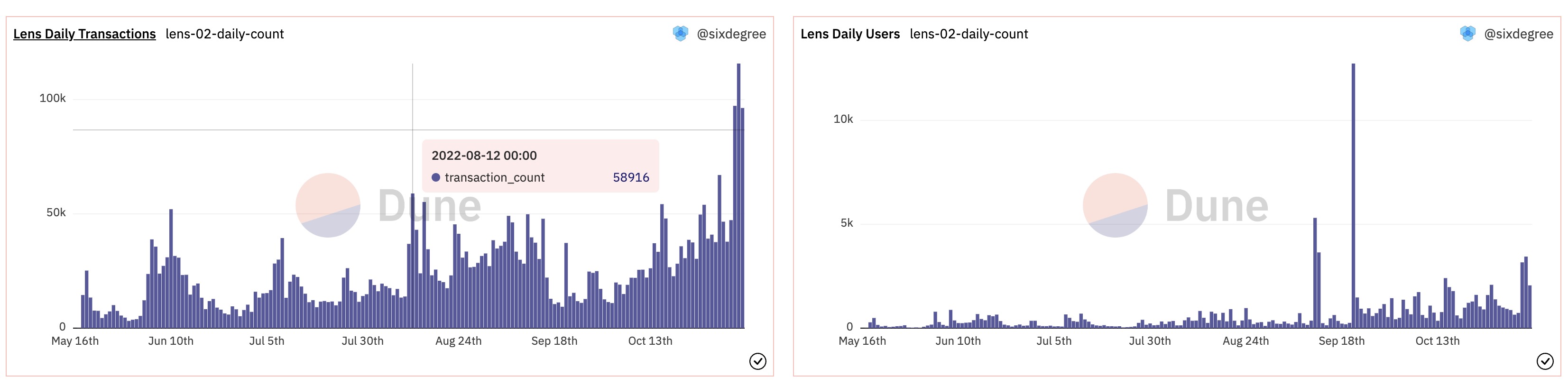
保存查询并为其添加两个Bar Chart类型的可视化图表,Y column 1对应的字段分别选择transaction_count和user_count,可视化图表的标题分别设置为“Lens Daily Transactions”和“Lens Daily Users”。将它们分别添加到数据看板中。效果如下图所示:
通常在按日期统计查询到时候,我们可以按日期将相关数据汇总到一起,计算其累计值并将其与每日数据添加到同一张可视化图表中,以便对整体的数据增长趋势有更直观的认识。通过使用sum() over ()窗口函数,可以很方便地实现这个需求。为了保持逻辑简单易懂,我们总是倾向于使用CTE来将复杂的查询逻辑分解为多步。将上面的查询修改为:
with daily_count as (
select date_trunc('day', block_time) as block_date,
count(*) as transaction_count,
count(distinct "from") as user_count
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date
group by 1
order by 1
)
select block_date,
transaction_count,
user_count,
sum(transaction_count) over (order by block_date) as accumulate_transaction_count,
sum(user_count) over (order by block_date) as accumulate_user_count
from daily_count
order by block_date
查询执行完毕后,我们可以调整之前添加的两个可视化图表。分别在Y column 2下选择accumulate_transaction_count和accumulate_user_count将它们作为第二个指标值添加到图表中。由于累计值跟每天的数值往往不在同一个数量级,默认的图表显示效果并不理想。我们可以通过选择“Enable right y-axis”选项,然后把新添加的第二列设置为使用右坐标轴,同时修改其“Chart Type”为“Area”(或者“Line”,“Scatter”),这样调整后,图表的显示效果就比较理想了。
为了将每日交易数量与每日活跃用户数量做对比,我们可以再添加一个可视化图表,标题设置为“Lens Daily Transactions VS Users”,在Y轴方向分别选择transaction_count和user_count列。同样,因为两项数值不在同一个数量级,我们启用右侧坐标轴,将user_count设置为使用右坐标轴,图表类型选择“Line”。也将这个图表添加到数据看板。通过查看这个图表,我们可以看到,在2022年11月初的几天里,Lens的每日交易量出现了一个新的高峰,但是每日活跃用户数量的增长则没有那么明显。
这里需要额外说明的是,因为同一个用户可能中不同的日期都有使用Lens,当我们汇总多天的数据到一起时,累计得到的用户数量并不代表实际的独立用户总数,而是会大于实际用户总数。如果需要统计每日新增的独立用户数量及其总数,我们可以先取得每个用户最早的交易记录,然后再用相同的方法按天汇总统计。具体这里不再展开说明,请大家自行尝试。另外如果你想按周、按月来统计,只需Fork这个查询,修改date_trunc()函数的第一个参数为“week”或者“month”即可实现。作为对比,我们Fork并修改了一个按月统计的查询,只将其中的“”加到了数据看板中。
调整完成后,数据看板中的图表会自动更新为最新的显示结果,如下图所示。
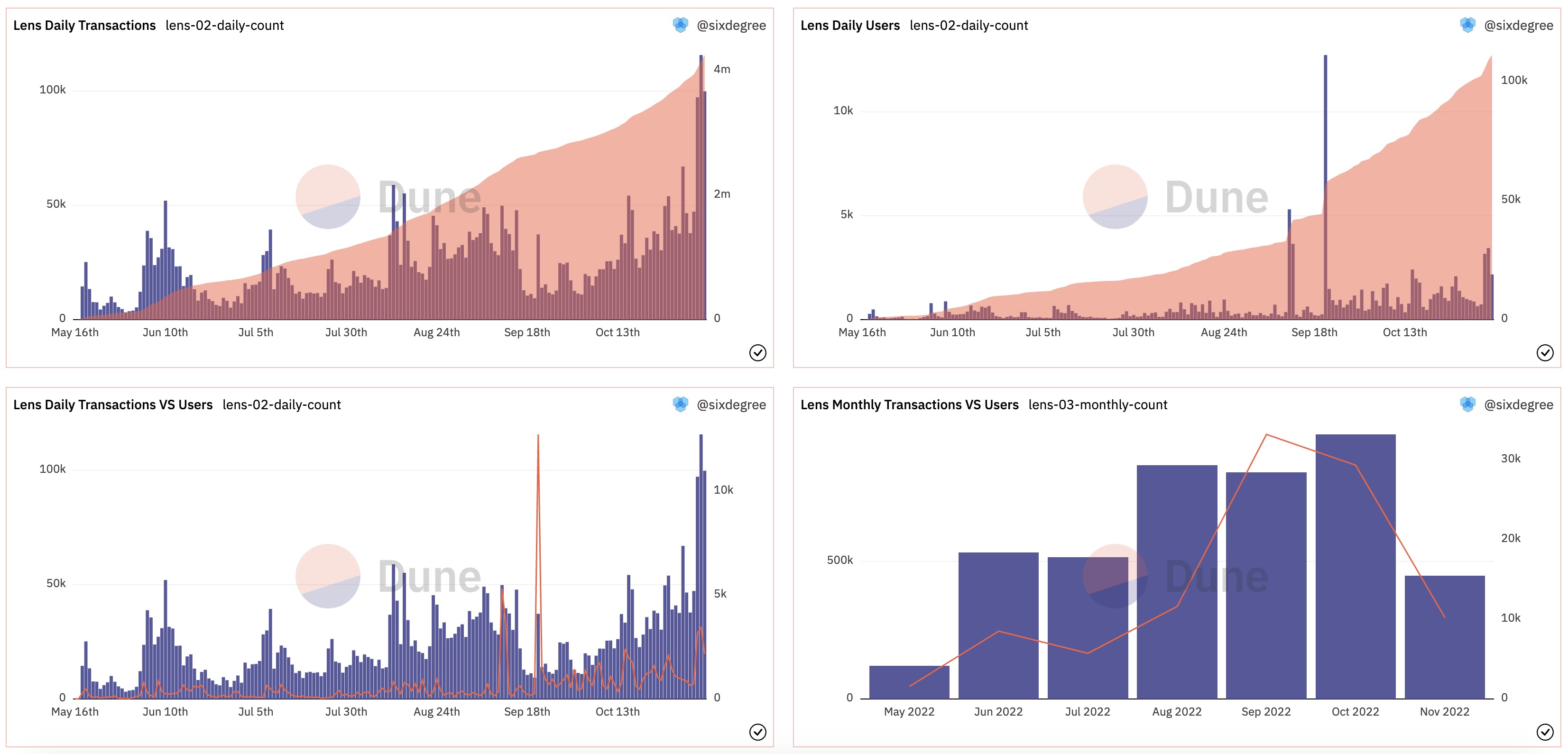
以上两个查询在Dune上的参考链接:
创作者个人资料(Profile)数据分析
Lens的创作者个人资料账号目前仅限于许可白名单内的用户来创建,创建个人资料的数据保存在createProfile表中。用下面的查询,我们可以计算出当前已经创建的个人资料的数量。
select count(*) as profile_count
from lens_polygon.LensHub_call_createProfile
where call_success = true -- Only count success calls
创建一个Counter类型的可视化图表,Title设置为“Total Profiles”,将其添加到数据看板中。
我们同样关心创作者个人资料随日期的变化和增长情况。用下面的查询可以统计出每日、每月的个人资料创建情况。
with daily_profile_count as (
select date_trunc('day', call_block_time) as block_date,
count(*) as profile_count
from lens_polygon.LensHub_call_createProfile
where call_success = true
group by 1
order by 1
)
select block_date,
profile_count,
sum(profile_count) over (order by block_date) as accumulate_profile_count
from daily_profile_count
order by block_date
用类似的方法创建并添加可视化图表到数据看板。显示效果如下图所示:
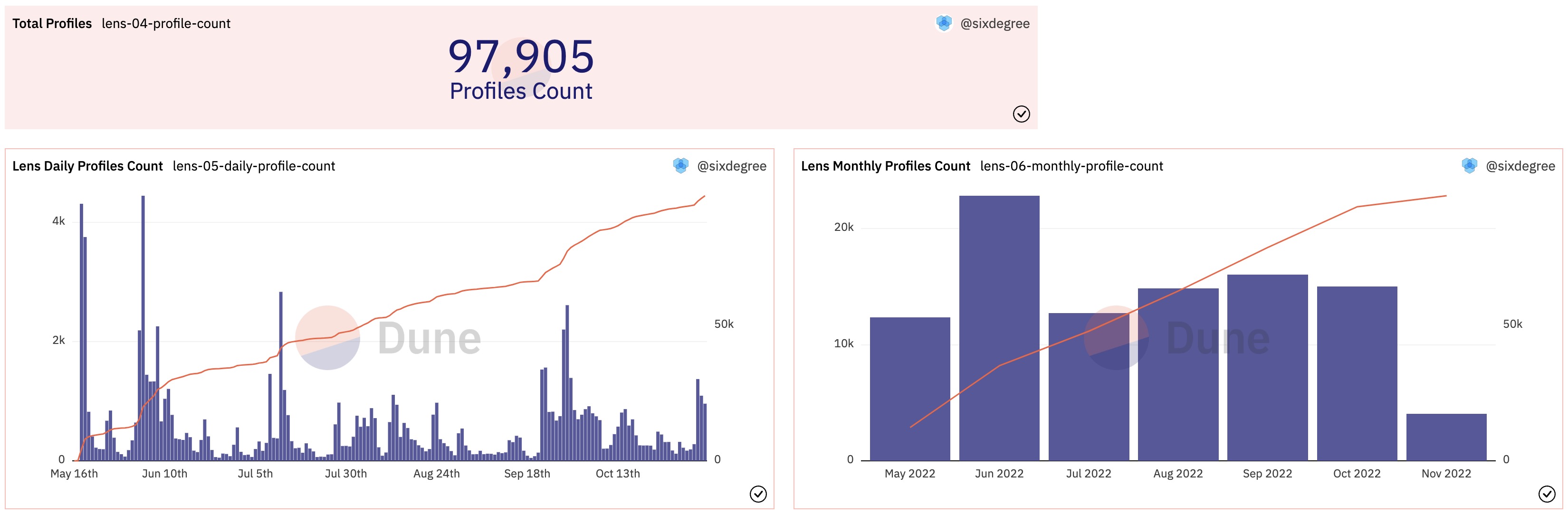
以上两个查询在Dune上的参考链接:
创作者个人资料域名分析
Lens致力于打造一个社交图谱生态系统,每个创作者可以给自己的账号设置一个个性化的名称(Profile Handle Name),这也是通常大家说的Lens域名。与ENS等其他域名系统类似,我们会关注一些短域名、纯数字域名等的注册情况、不同字符长度的域名已注册数量等信息。在createProfile表中,字段vars以字符串格式保存了一个json对象,里面就包括了用户的个性化域名。在Dune V2中,我们可以直接使用:符号来访问json字符串中的元素的值,例如用vars:handle获取域名信息。
使用下面的SQL,我们可以获取已注册Lens域名的详细信息:
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle') , '.lens', '') as short_handle_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
为了统计不同长度、不同类型(纯数字、纯字母、混合)Lens域名的数量以及各类型下已注册域名的总数量,我们可以将上面的查询放到一个CTE中。使用CTE的好处是可以简化逻辑(你可以按顺序分别调试、测试每一个CTE)。同时,CTE一经定义,就可以在同一个查询的后续SQL脚本中多次使用,非常便捷。鉴于查询各类域名的已注册总数量和对应不同字符长度的已注册数量都基于上面的查询,我们可以在同一个查询中将它们放到一起。因为前述统计都需要区分域名类型,我们在这个查询中增加了一个字段handle_type来代表域名的类型。修改后的查询代码如下:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
(case when regexp_like(replace(json_value(vars, 'lax $.handle'), '.lens', ''), '^[0-9]+$') then 'Pure Digits'
when regexp_like(replace(json_value(vars, 'lax $.handle'), '.lens', ''), '^[a-z]+$') then 'Pure Letters'
else 'Mixed'
end) as handle_type,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
),
profiles_summary as (
select (case when length(short_name) >= 20 then 20 else length(short_name) end) as name_length,
handle_type,
count(*) as name_count
from profile_created
group by 1, 2
),
profiles_total as (
select count(*) as total_profile_count,
sum(case when handle_type = 'Pure Digits' then 1 else 0 end) as pure_digit_profile_count,
sum(case when handle_type = 'Pure Letters' then 1 else 0 end) as pure_letter_profile_count
from profile_created
)
select cast(name_length as varchar) || ' Chars' as name_length_type,
handle_type,
name_count,
total_profile_count,
pure_digit_profile_count,
pure_letter_profile_count
from profiles_summary
join profiles_total on true
order by handle_type, name_length
修改后的查询代码相对比较复杂,解读如下:
- CTE
profile_created通过使用“:“符号来从保存于vars字段中的json字符串里面提取出Profile的域名信息和域名归属的用户地址。由于保存的域名包括了.lens的后缀,我们通过replace()方法将后缀部分清除并命名新的字段为short_name,方便后面计算域名的字符长度。进一步,我们通过一个CASE语句,结合正则表达式匹配操作符rlike来判断域名是否由纯数字或者纯字母组成,并赋予一个字符串名称值,命名此字段为handle_type。可参考rlike operator了解正则表达式匹配的更多信息。 - CTE
profiles_summary基于profile_created执行汇总查询。我们首先使用length()函数计算出每一个域名的字符长度。因为存在少量特别长的域名,我们使用一个CASE语句,将长度大于20个字符的域名统一按20来对待。然后我们基于域名长度name_length和handle_type执行group by汇总统计,计算各种域名的数量。 - CTE
profiles_total中,我们统计域名总数量、纯数字域名的数量和纯字母域名的数量。 - 最后,我们将
profiles_summary和profiles_total这两个CTE关联到一起输出最终查询结果。由于profiles_total只有一行数据,我们直接使用true作为JOIN的条件即可。另外,因为name_length是数值类型,我们将其转换为字符串类型,并连接到另一个字符串来得到可读性更强的域名长度类型名称。我们将输出结果按域名类型和长度进行排序。
执行查询并保存之后,我们为其添加下列可视化图表并分别添加到数据看板中:
- 添加两个Counter,分别输出纯数字域名的数量和纯字母域名的数量。因为之前已经有一个域名注册总数量的Counter,我们可以将这两个新的Counter图表跟它放置到同一行。
- 添加一个域名类型分布的扇形图(Pie Chart),Title设置为“Profiles Handle Name Type Distribution”,“X Column“选择
handle_type字段,“Y Column 1”选择name_count字段。 - 添加一个域名长度分布的扇形图(Pie Chart),Title设置为“Profiles Handle Name Length Distribution”,“X Column“选择
name_length_type字段,“Y Column 1”选择name_count字段。 - 添加一个域名长度分布的柱状图(Bar Chart),Title设置为“Profiles Handle Name Count By Length”,“X Column“选择
name_length_type字段,“Y Column 1”选择name_count字段,“Group by”选择handle_type字段。同时取消勾选“Sort values”选项,再勾选“Enable stacking”选项。 - 添加一个域名长度分布的面积图(Area Chart),Title设置为“Profile Handle Name Count Percentage By Type”,“X Column“选择
name_length_type字段,“Y Column 1”选择name_count字段,“Group by”选择handle_type字段。取消勾选“Sort values”选项,再勾选“Enable stacking”选项,另外再勾选“Normalize to percentage”选项。
将上述可视化图表全部添加到数据看板中,调整显示顺序后,如下图所示:
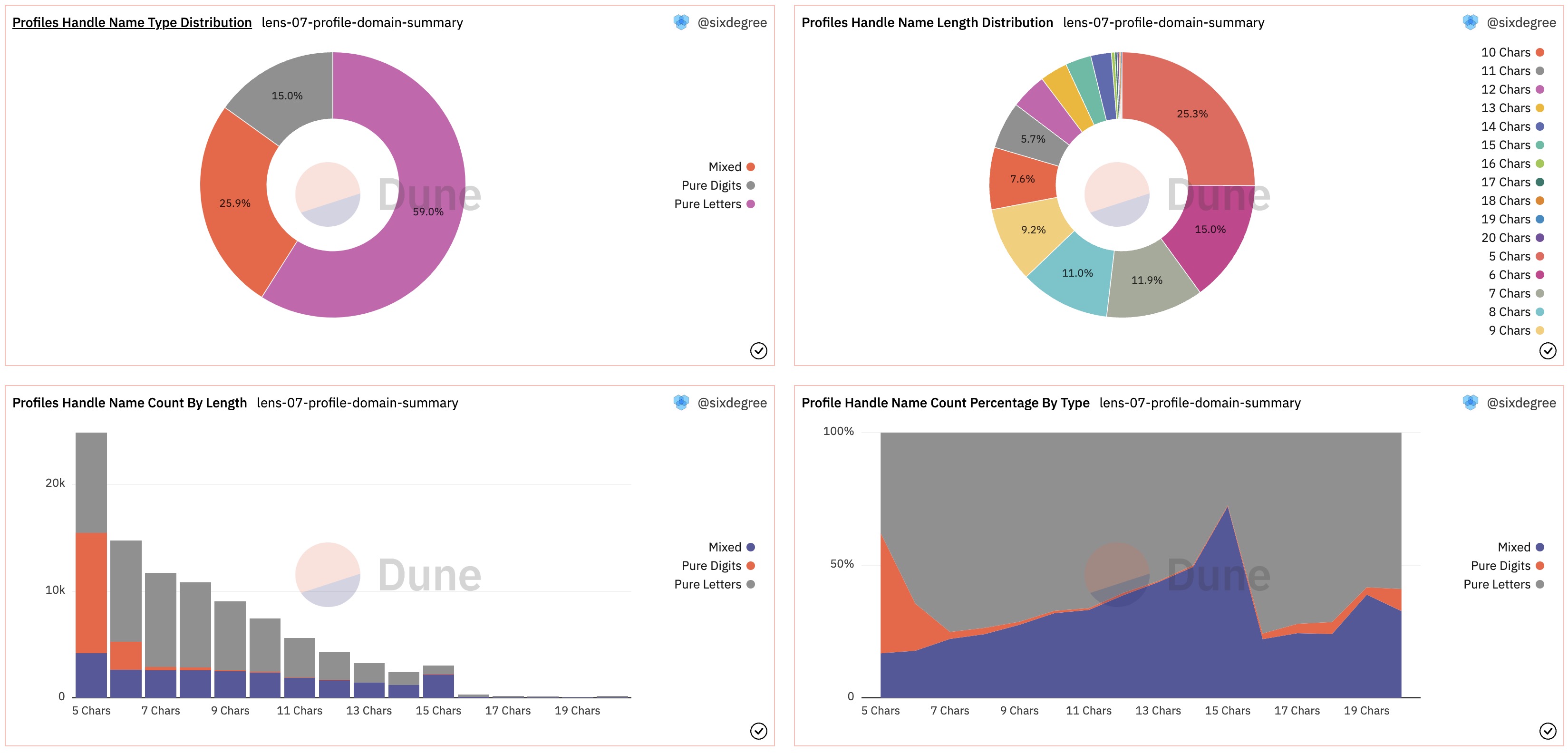
本查询在Dune上的参考链接:
已注册域名搜索
除了对已注册Lens域名的分布情况的跟踪,用户也关注已注册域名的详细情况。为此,可以提供一个搜索功能,允许用户搜索已注册域名的详细列表。因为目前已经注册了约10万个Lens账号,我们在下面的查询中限制最多返回10000条搜索结果。
首先,我们可以在查询中定义一个参数{{name_contains}}(Dune 使用两个花括号包围住参数名称,默认参数类型为字符串Text类型)。然后使用like关键词以及%通配符来搜索名称中包含特定字符的域名:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
)
select call_block_time,
profile_id,
handle_name,
short_name,
call_tx_hash
from profile_created
where short_name like '%{{name_contains}}%' -- 查询名称包含输入的字符串的域名
order by call_block_time desc
limit 1000
在查询执行之前,Dune 引擎会用输入的参数值替换SQL语句中的参数名称。当我们输入“john”时,where short_name like '%{{name_contains}}%'子句会被替换为where short_name like '%john%',其含义就是搜索short_name包含字符串john的所有域名。注意虽然参数类型是字符串类型,但是参数替换时不会字段给我们添加前后的单引号。单引号需要我们直接输入到查询中,如果忘记输入了则会引起语法错误。
如前所述,域名的长度也很关键,越短的域名越稀缺。除了搜索域名包含的字符,我们可以再添加一个域名长度过滤的参数{{name_length}},将其参数类型修改为下拉列表类型,同时填入数字5-20的序列作为参数值列表,每行一个值。因为Lens域名目前最少5个字符,而且超过20个字符的域名很少,所以我们选择5到20作为区间。参数设置如下图所示。
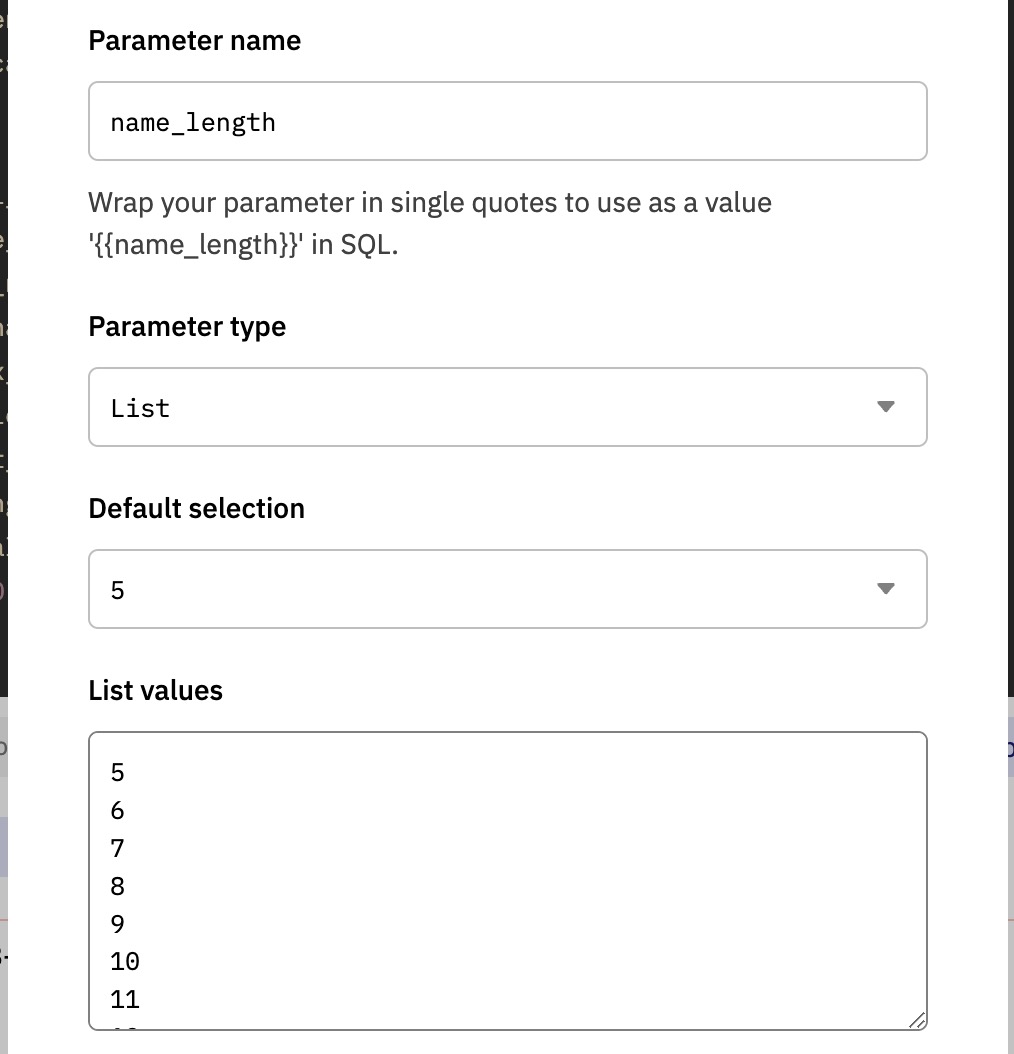
添加了新的参数后,我们调整SQL语句的WHERE子句为如下所示。其含义为查询名称包含输入的关键字,同时域名字符长度等于选择的长度值的域名列表。注意,虽然我们的name_length参数的值全部是数字,但List类型参数的默认类型是字符串,所以我们使用cast()函数转换其类型为整数类型后再进行比较。
where short_name like '%{{name_contains}}%' -- 名称包含输入的字符串的域名
and length(short_name) = cast('{{name_length}}' as integer) -- 域名长度等于选择的长度值
同样,我们可以再添加一个域名字符串模式类型的参数{{name_pattern}},用来过滤纯数字域名或纯字母域名。这里同样设置参数为List类型,列表包括三个选项:Any、Pure Digits、Pure Letters。SQL语句的WHERE子句相应修改为如下所示。跟之前的查询类似,我们使用一个CASE语句来判断当前查询域名的类型,如果查询纯数字或者纯字母域名,则使用相应的表达式,如果查询任意模式则使用1 = 1这样的总是返回真值的相等判断,相当于忽略这个过滤条件。
where short_name like '%{{name_contains}}%' -- 名称包含输入的字符串的域名
and length(short_name) = cast('{{name_length}}' as integer) -- 域名长度等于选择的长度值
and (case when '{{name_pattern}}' = 'Pure Digits' then regexp_like(short_name, '^[0-9]+$')
when '{{name_pattern}}' = 'Pure Letters' then regexp_like(short_name, '^[a-z]+$')
else 1 = 1
end)
因为我们在这几个搜索条件之间使用了and连接条件,相当于必须同时满足所有条件,这样的搜索有一定的局限性。我们对其做适当调整,name_length参数也再增加一个默认选项“0”。当用户未输入或者未选择某个过滤条件时,我们忽略它。这样搜索查询就变得非常灵活了。完整的SQL语句如下:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
)
select call_block_time,
profile_id,
handle_name,
short_name,
'<a href=https://polygonscan.com/tx/' || cast(call_tx_hash as varchar) || ' target=_blank>Polyscan</a>' as link,
call_tx_hash
from profile_created
where (case when '{{name_contains}}' <> 'keyword' then short_name like '%{{name_contains}}%' else 1 = 1 end)
and (case when cast('{{name_length}}' as integer) < 5 then 2 = 2
when cast('{{name_length}}' as integer) >= 20 then length(short_name) >= 20
else length(short_name) = cast('{{name_length}}' as integer)
end)
and (case when '{{name_pattern}}' = 'Pure Digits' then regexp_like(short_name, '^[0-9]+$')
when '{{name_pattern}}' = 'Pure Letters' then regexp_like(short_name, '^[a-z]+$')
else 3 = 3
end)
order by call_block_time desc
limit 1000
我们给这个查询增加一个表格(Table)类型的可视化图表,并将其添加到数据看板中。当添加代参数的查询到数据看板时,所有的参数也被自动添加到看板头部。我们可以进入编辑模式,拖拽参数到其希望出现的位置。将图表加入数据看板后的效果图如下所示。
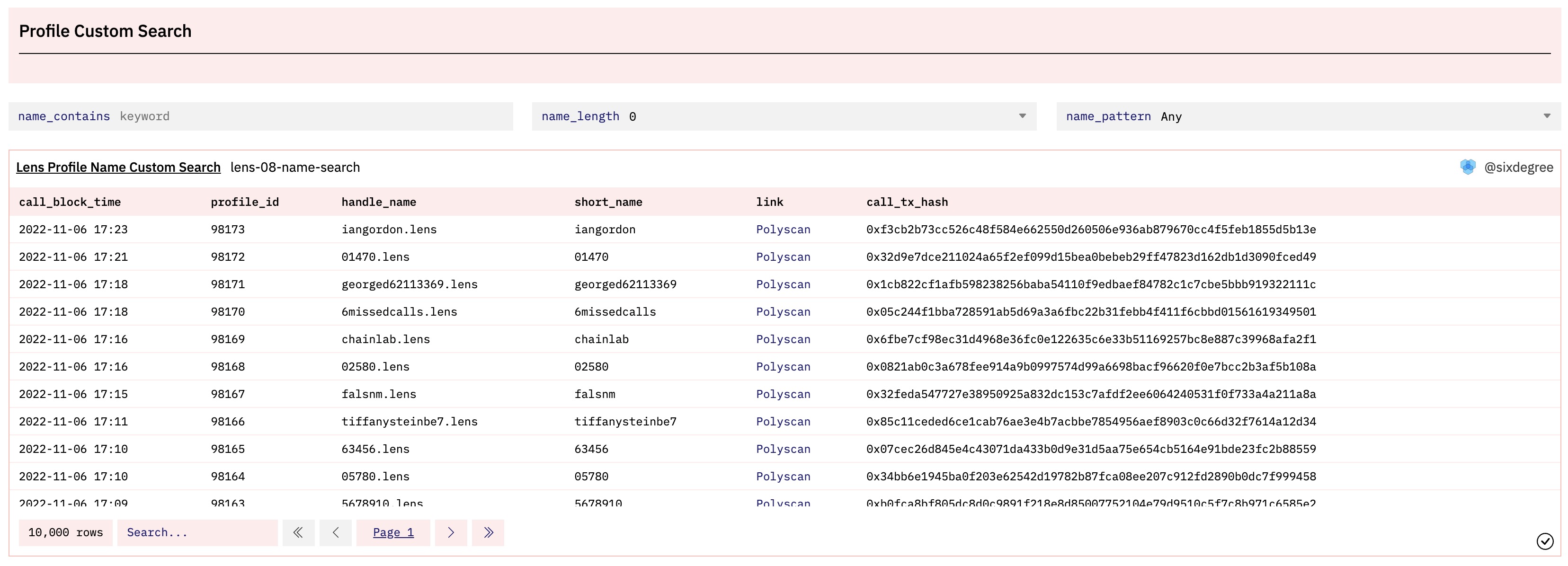
以上查询在Dune上的参考链接:
- https://dune.com/queries/1535903
- https://dune.com/queries/1548540
- https://dune.com/queries/1548574
- https://dune.com/queries/1548614
总结
至此,我们已经完成了对Lens协议的基本概况和创作者个人资料、域名信息的分析,也添加了一个域名搜索功能。前面“数据看板的主要分析内容”部分我们列出了更多可以分析的内容,在本篇教程的第二部分,我们将继续围绕创作者发布的出版物、关注、收藏、NFT等方面进行分析。你也可以自行探索创建新的查询。
作业
请结合教程内容,制作你自己的Lens 协议数据看板,可参考“数据看板的主要分析内容”部分提示的内容尝试新的查询分析。请大家积极动手实践,创建数据看板并分享到社区。我们将对作业完成情况和质量进行记录,之后追溯为大家提供一定的奖励,包括但不限于Dune社区身份,周边实物,API免费额度,POAP,各类合作的数据产品会员,区块链数据分析工作机会推荐,社区线下活动优先报名资格以及其他Sixdegree社区激励等。
SixdegreeLab介绍
SixdegreeLab(@SixdegreeLab)是专业的链上数据团队,我们的使命是为用户提供准确的链上数据图表、分析以及洞见,并致力于普及链上数据分析。通过建立社区、编写教程等方式,培养链上数据分析师,输出有价值的分析内容,推动社区构建区块链的数据层,为未来广阔的区块链数据应用培养人才。
欢迎访问SixdegreeLab的Dune主页。
因水平所限,不足之处在所难免。如有发现任何错误,敬请指正。